What is Stable Diffusion
 jenxi.com
jenxi.com Vision alchemist crafting strategic innovation & AI adoption. Bridging startups to China's ecosystem advantage. Building a cyberbrain. Registered pharmacist × Brand strategist × Storyteller
When I first started posting my AI art, many people reached out to me asking how I made the art pieces because they were different from those circulating the internet. After I posted about my AI art journey, the questions became “What is Stable Diffusion” and, for those who have tried Stable Diffusion, “How do you get such results?”
Compared to images you see on social media and on the web, the key difference is due to my insistence on generating realistic images with a lot of details that are not easy to achieve with just prompting alone.

Cyber wuxia Yan by Jenxi
This is partly due to my personal goal of trying to see how close generative AI can get to realism, and also because I wanted to see how AI would impact my business since visual content generation is a big part of it.
I’m aware of this obsession with realism, and the need to drop this fixation to spend more time on improving my composition, but I digress.
Keep your feedback coming as your voice is invaluable in shaping the content I put out. My goal is to share what I’ve learnt so you can skip past the hundreds of hours I poured into research and trial-and-error. If you find this content helpful in any way, consider buying me a coffee on Ko-fi or join my Patreon to get my art in glorious high resolution.
Let’s dive into the captivating world of Stable Diffusion, where imagination and algorithms join forces to create art like never before.
Unraveling the Mystery: What is Stable Diffusion?
Stable Diffusion, in simple terms, is a remarkable technique that uses the power of artificial intelligence to create stunning and mesmerizing images. It simulates the process of colors or patterns spreading and blending harmoniously, resulting in visually captivating transformations.
What’s in a name? Well, it can aptly describe what something is but confuse beginners. We learnt about diffusion in chemistry class, so how is it related to artificial intelligence and machine learning? And why is it stable? What happens if it’s unstable? (You don’t want to know what Unstable Diffusion is. Yes, it’s a thing and it’s NSFW.)
The term “Stable” in the name comes from the startup Stability AI that developed Stable Diffusion model. “Diffusion” refers to it being a latent diffusion model.
Before I start, I’d like to make it clear that I’m not a machine learning expert. What I share here is my understanding of Stable Diffusion. While I do my best to provide accurate information and explanations, I’m also well aware that I might be completely wrong. Please feel free to correct me where I’m wrong. This is what learning in public is all about.

Water mage by Jenxi
The Mechanics of Stable Diffusion
So, let’s get down to demystifying Stable Diffusion. You probably remember diffusion from chemistry class. If you don’t or aren’t familiar with it, I’ll try to explain it with an analogy.
Core Concept: Diffusion
Imagine you’re in a room filled with coloured smoke. At first, the colours might be clustered, forming pockets of intensity. Diffusion occurs when these clusters gradually spread and blend until the entire room is a harmonious mix of hues.
Stable Diffusion operates on a similar principle, but with data and features instead of colours. It’s like a digital artist’s brushstroke, smoothly transitioning and merging details to create a seamless and realistic image. This process ensures that every element in the artwork harmonises, resulting in a refined and captivating visual.
In machine learning, diffusion models learn the latent structure of a dataset by modelling how data points diffuse through the latent space, where items that resemble each other are positioned close to each other.
In computer vision, the neural network is trained to denoise blurred images with Gaussian noise by learning to reverse the diffusion process.

Stable Diffusion denoising process. Source: Wikipedia
{kind=link}
The Foundation: Generative Adversarial Networks (GANs)
To understand Stable Diffusion, you need to get acquainted with Generative Adversarial Networks, or GANs for short.
Imagine there are two forces in the neural network – a generator and a discriminator. The generator’s job is to conjure up images with the aim of creating something that resembles reality. The discriminator then decides if the generated image is real or a computer-generated imitation.
This is where things get interesting. The generator learns from the discriminator’s feedback and is constantly improving its ability to create increasingly convincing images. Likewise, the discriminator is also getting better at determining whether the images are real. It is a never-ending dance to keep pushing towards increasingly higher performance to produce images that are very close to reality.
This is what makes GANs so powerful in AI image generation.
The Algorithmic Dance: GANs in Stable Diffusion
How does all this tie into Stable Diffusion? Imagine a Taichi master directing these two forces to achieve perfect balance and harmony. Stable Diffusion operates on the principle of probability by leveraging the inherent uncertainty and randomness in the generation process. It fine-tunes the interplay between the generator and discriminator in a GAN, enhancing its ability to generate images that are highly detailed and and realistic.
Through meticulous adjustments to the training process, we are able to train the algorithm to generate results with increasingly higher quality and more refined outputs.
The Potential of Stable Diffusion
Stable Diffusion is a transformative technique that represents a significant leap forward in generative art that has taken the world by storm.
Elevating Artistic Expression with AI
This technique opens up a world of possibilities for artists, photographers, and creatives. Stable Diffusion acts as a catalyst, enhancing the artist’s ability to express themselves through the synergy of human creativity and artificial intelligence.
It’s a tool that empowers us to explore uncharted territories, unlocking styles and concepts that were once beyond imagination. With Stable Diffusion, artists transcend the limitations of conventional art creation, venturing into a realm where imagination knows no bounds.
Beyond Basics: Exploring Concepts
What does that mean? You’ve probably seen some AI generated images and know that AI can generate images of a person or an object. It is able to imitate an artist’s style, painting medium, painting style. It can also reproduce photographs based to the focal length, lighting, or a specific type of look or a photographer’s style. It can even understand composition and placement of subjects. But there’s more to generative AI.
We can go beyond just a look or style. You can train concepts such as a pose or pattern. It is able to learn what different clothing look like. You can even train textures or materials. A stormtrooper from Star Wars wearing armour made of blue and white porcelain. Or a mage conjuring water or magic.

Porcelain stormtrooper by Jenxi blends blue and white designs on the ceramic armour
You can even create what we call world morphs. These are concepts that influence and transform everything that appears in the world, hence the name. From cyberpunk to steampunk that we are familiar with, all the way to fantasy worlds where candy, bones or mushrooms dominate the world.
Whatever concept you can come up with, you can attempt to train with Stable Diffusion. And this is just scratching the surface. You can merge concepts to create images generated based on concepts that are out of this world. The limit is your imagination.
Stable Diffusion is an open invitation to artists to break free from the confines of established styles and concepts. It’s a gateway to uncharted territories, where the exploration of diverse artistic expressions becomes not just possible, but exhilarating. Whether it’s blending genres, experimenting with new techniques, or venturing into unexplored thematic realms, Stable Diffusion empowers artists to bring their imaginations to life.
Bridging the Gap: The Human-AI Collaboration
If you’re an artist who is still adamant on boycotting generative AI for ethical reasons, I urge you to give it a try. You can maintain your stance while experimenting in private for research purposes. Stable Diffusion heralds a new era in artistic methodologies and I believe every artist should try to understand what a powerful tool it can be.
It redefines how artists approach their craft, introducing innovative techniques that fuse human intuition with the capabilities of generative AI. The result is a dynamic interplay that pushes the boundaries of what’s achievable, paving the way for novel creative processes and groundbreaking artistic endeavours, not dissimilar to how Photoshop and digital painting and photography has transformed the art world.

AI self portrait of Jenxi
Stable Diffusion is not just a tool. It’s a creative partner that harmonises the human touch with the precision of AI. The results are collaborative works that transcend individual capabilities. The artist and the algorithm engage in a symbiotic dance, each contributing their strengths to craft art that is a testament to the potential of human-AI collaboration. Together, they bridge the gap between traditional artistic methods and the cutting-edge world of AI-generated art.
Tradition meets innovation as Stable Diffusion blurs the lines between conventional and digital art forms. It challenges preconceived notions about the boundaries of artistic expression, proving that the digital realm is a canvas as versatile and expressive as any traditional medium. This paradigm shift invites artists and audiences alike to embrace the limitless possibilities offered by technology in the pursuit of creative excellence.
AI-generated art is at this intersection that innovation flourishes, birthing a new breed of art that resonates with the digital age.
Comparing Stable Diffusion with Midjourney, & DALL-E
Stable Diffusion, Midjourney, and DALL-E represent the vanguard of AI art generation, each with its distinctive approach and its own set of strengths and limitations. I’ve listed down the key pros and cons that a beginner should consider.
DALL-E
Pros:
-
Easy to use. DALL-E has a simple interface with minimal learning curve, making it easy for beginners to learn.
-
Hosted resources. It’s an online service so you leverage on OpenAI’s servers to do the processing.
Cons:
-
Limited creative options. DALL-E’s simplicity means you rely on text prompting to generate images.
-
Pay to use. You need to buy credits to generate images. Each prompt generates four images and uses one credit. It costs USD 15 for 115 credits, that’s around USD 0.13 per prompt or USD 0.0325 per image. It used to give out free monthly credits but that option is gone.
Midjourney
Pros:
-
Amazing output. Midjourney is probably the most well-known among the three, or even all computer vision tools, for the highly artistic images it can generate with simple prompts.
-
Many resources available. There are many Midjourney prompts out there for you to refer and use to generate images.
Cons:
-
Pay to use. While DALL-E uses a credit system, Midjourney charges a monthly subscription that limits the number of generation or the duration of the generation. For example, the basic plan is limited to 200 generations per month, while the standard and pro plans get unlimited relaxed generations and 15 hours and 30 hours of fast generations respectively.
-
Account required. You need to register for a Discord account to join Midjourney’s server to use it. Not a hassle if you already have an account. There are many Discord servers for AI communities, so it’s a good idea to get an account to access them.
-
Not as easy as DALL-E. There is a slight learning curve in learning the commands for the Discord bot to generate images.
Stable Diffusion
Pros:
-
Most powerful out of the three. With Stable Diffusion, you get better control over the output and there are tools to train custom models. Midjourney generates output that is arguably better, depending on your tastes, but this point becomes moot once you discover that you can train Stable Diffusion models to imitate the Midjourney style.
-
You can run it locally. This let you customise how you run it and if you have a decent GPU, you can get generate outputs faster and at higher resolutions compared to the other two.
-
Free! It’s free to use and open source.
-
Large amount of resources. There is a large amount of custom models trained by others, ready for you to use. I current have over 2,000 models.
Cons:
-
Most difficult out of the three. Stable Diffusion has a steeper learning curve since there are more options and tools available.
-
Work needed to get it running. The installation process might be a hurdle, especially if you’re not used to working with Python. There are one-click installers, but things move so fast in the world of Stable Diffusion, so expect breakage and problems.
-
Hardware requirements. You need a decent setup, including at least 6 to 8 GB of VRAM and enough storage space. How much space do you need? Models range from several MBs to 10 GBs. My 2,000 plus models take up almost 2 TBs of space.
Using Stable Diffusion: Tools and Resources
There are several ways to use Stable Diffusion. You can use image generation sites that run on Stable Diffusion, run Stable Diffusion on a cloud service, or install it locally.
Image generation sites
Use an online service if you prefer not to go through the hassle of setting up a local installation of Stable Diffusion, or if your machine is unable to run Stable Diffusion. The more popular ones are RunDiffusion, Mage Space and PixAI. I started out using NightCafe. And there’s also Dream Studio from Stability AI themselves.
Like Midjourney and DALL-E, these sites have to pay for the site development, hosting, and maintenance costs on top of the GPU processing cost to generate images for you. So they all require you either pay a subscription or buy credits.
These sites ensure that the models and different extensions work well so you can focus on your AI art generation without worrying about the technicalities.
Run an online instance
If you don’t want or are unable to run Stable Diffusion locally, there’s another option available for you. You can run Stable Diffusion online by using Google Colaboratory, or Colab for short. Google Colab allows you to run Python code on Google’s server using your Google Drive to store the models and images generated.
People were using Google Colab to run Stable Diffusion for free but Google has since changed their policies to require a Colab Pro subscription of USD 9.99 per month to run Stable Diffusion on Colab.
You can easily get started using the Fast Stable Diffusion Colab notebook shared by TheLastBen. The instructions are in the notebook and you can get your Stable Diffusion up and running pretty quickly.
Alternatives include Hugging Face spaces and Runpod.
When you use an online instance, you pay based on your GPU usage. The advantage of this over image generation sites is greater control over the Stable Diffusion instance. You can run Stable Diffusion wherever you are since it is a cloud instance.
Local installation
You can install Stable Diffusion locally on your computer. You need a GPU with at least 6 GB of VRAM to run Stable Diffusion 1.5 and 2.1, and at least 8 GB of VRAM to run Stable Diffusion XL.
Stable Diffusion is available on GitHub. However, you will need to run it using a graphical user interface if you don’t want to operate it via a command prompt.
The most popular GUI is Stable Diffusion Web UI by AUTOMATIC1111. It is often referred to as the Automatic1111 Web UI or A1111. This is what I use for my AI image generation. It is very well-supported and I’ve witnessed it growing by leaps and bounds from version 1.4 to the current 1.6.
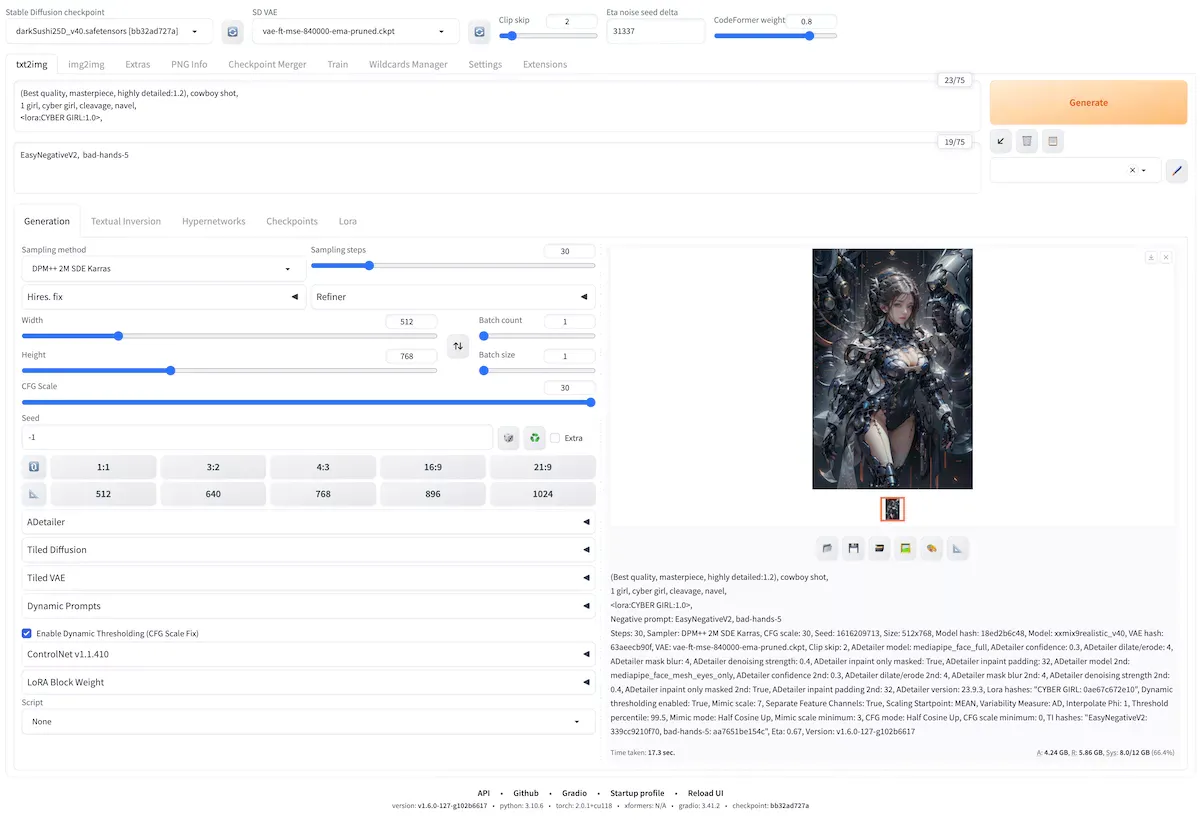
Stable Diffusion Web UI
There is a popular fork by vladmandic called SD.Next that started out adding improvements to the Automatic1111 WebUI but has since diverged so much that it is considered a standalone GUI for Stable Diffusion. It is sometimes referred to as Vlad’s Automatic.
Some, especially power users, swear by ComfyUI. It is another GUI that takes a modular approach to operating Stable Diffusion, allowing you to create advanced pipelines for your workflows. The complex nature of ComfyUI means that it has a steeper learning curve compared to A1111, but once you get the hang of it, it becomes a very powerful tool.
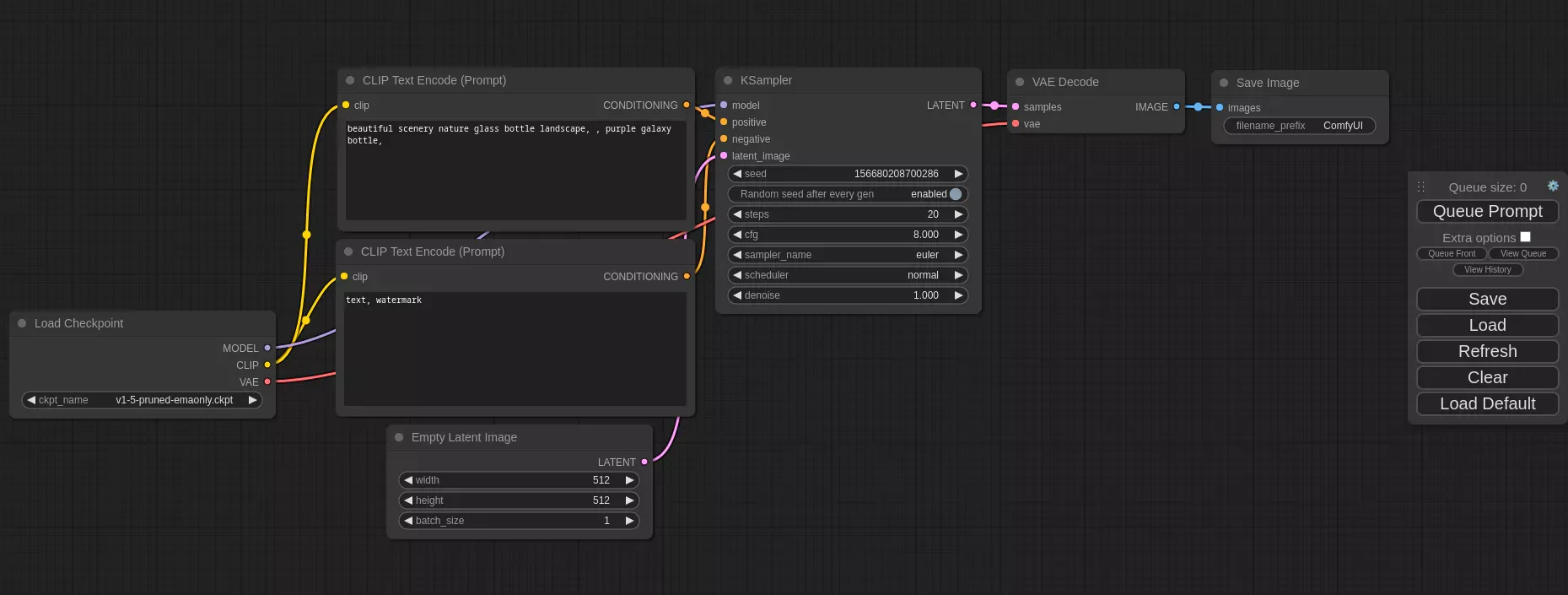
ComfyUI
Training tool
You can train models with Automatic1111 Web UI. For better control over the training setup and parameters, there’s Kohya’s Stable Diffusion training scripts. Like the A1111, you need a GUI to make operating it easier. The GUI for Kohya’s scripts is Kohya’s GUI by bmaltais, more commonly referred to as kohya_ss.
Resources
The two largest repositories for Stable Diffusion models are Civitai and Hugging Face.
Besides hosting models, Civitai also showcases user generated output from the models and has a discussion and review system to help the community gauge the quality of the models.
Hugging Face is the GitHub of machine learning. You find more than just Stable Diffusion models on the site. There are also other resources for computer vision, natural language processing, audio, and others.
Civitai is dedicated to Stable Diffusion and has a better features for the community. Due to Civitai’s popularity driving its rapid growth, the site was very unstable, though it has since improved vastly. So many creators upload their files on Hugging Face as a backup.
Start your Stable Diffusion journey
Stable Diffusion is a powerful tool. It is the most powerful of out the options available as I mentioned above. Of course, there are prolific AI artists who combine Midjourney and Stable Diffusion to produce amazing artwork. However, I would suggest focusing on mastering one tool first if you’re just getting started in AI art.

Mononoke Hime by Jenxi
I hope this overview gives a good introduction to Stable Diffusion and demystifies AI image generation. Share this article the next time someone asks, “What is Stable Diffusion?”
I’ll be sharing guides on how I use Stable Diffusion to generate art and answer some of the common questions I get to help you get started in computer vision. Pateron members get a peek at the behind-the-scenes of how certain pieces are made.
Ready to stay updated with the latest developments in Stable Diffusion, AI image generation, and explore exciting computer vision techniques? Subscribe to my newsletter where I share my journey and learnings.
Remember, with Stable Diffusion, the canvas becomes your playground, and the possibilities are limitless!